[Postgres] 資料庫裡的儲存概念
前言

本文主要探討資料庫裡的儲存概念,了解資料庫是如何將資料存在硬碟(Disk)裡,儲存原理在各家主流資料庫會有差異,但大方向是相同的,內容會以 Postgres 為主,少部分提及其他資料庫的做法。
本篇主要筆記 Udemy - SQL and PostgreSQL: The Complete Developer’s Guide 及 Udemy - Fundamentals of Database Engineering 的課程內容,但以自己較易理解的方式加以整理,可能和原課程內容有些出入。
資料庫儲存結構的相關名詞
了解主流的關聯式資料庫如何儲存資料前,須先對下面幾項名詞有所理解:
- Table
- Row_ID
- Tuple
- Page
- I/O
- Heap
- Index
Table
資料表由行(Column)、列(Row) 組成
Row_ID
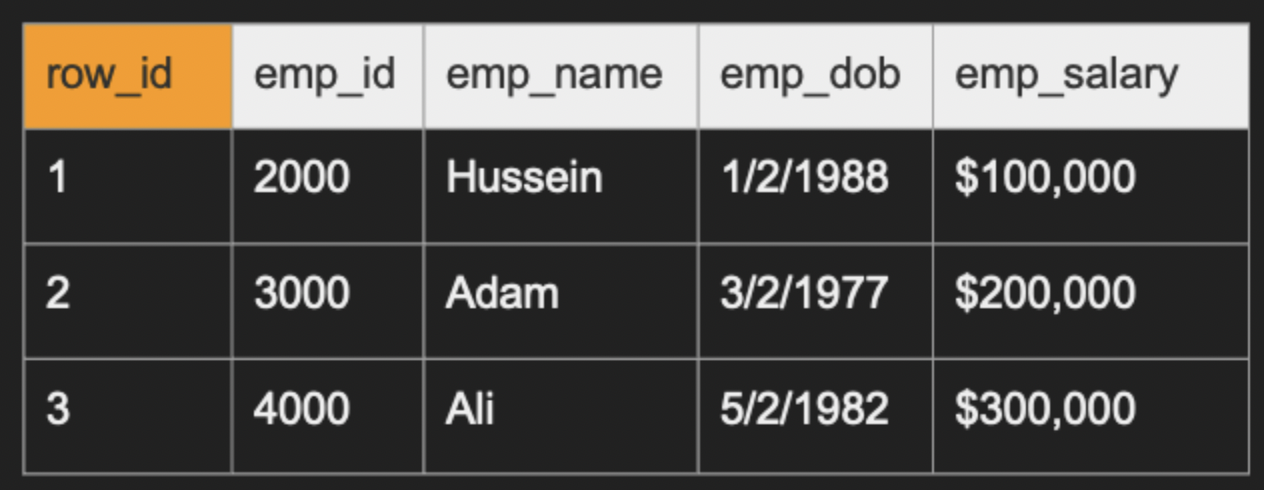
資料庫內部會對每筆資料自己額外建一個 row_id,由系統維護
這部分因各家資料庫有所差異:
- MySQL (innoDB) 的主鍵和 row_id 是同一個。
- Postgres 則是有個系統生成的欄位
row_id
Tuple (or Item)
指的是資料表裡的一筆資料(即一個 row),這些 tuple 會被存放到 Page 上,後續有圖片說明他們之間的關係。
每個 Tuple 都有個別的 ID,簡稱 TID,在 Postgres 裡面等同 row id,其內容包含:
- block number: Block 的位置編號
- tuple index within block(Offset): tuple 位於該 block 的位置
關於 Tuple 相關說明,摘錄自 PG 官方文件內容:Object Identifier Types
A final identifier type used by the system is tid, or tuple identifier (row identifier). This is the data type of the system column ctid. A tuple ID is a pair (block number, tuple index within block) that identifies the physical location of the row within its table.
範例: TID = (3,10)
表示該 tuple 資料位於第 11 個(編號從 0 開始) block 內的第 3 個 element。
TID 會和後續 Index 存放的內容息息相關,後面會提到。
Page(or Block)
- Page 用於存放資料表的所有資料,故每張 Page 裡會有多個 Tuple
- 根據不同的儲存模型,資料存在 Page 的方式不同
- 資料庫讀取資料的方式:單次 I/O 讀取一張 or 多張表的資料
- 每張表都有固定的大小 (e.g. 8KB in postgres and sql server, 16KB in MySQL)
範例: 一張 Page 可放 3 個 Row,若有 1001 筆,則會有 334 個 Page (1001/3 = 333 ~, 多的兩筆需加一個 Page 存放)
影響 query 效能好壞的關鍵:
單個 query 讀取多少的 Page、產生了幾次 I/O
I/O
input/output 又作 I/O
- 用於表示向 Disk 發出讀取的請求
- 盡可能減少 I/O 次數 → 單個查詢的 I/O 次數越少,查詢的回應速度越快
- 單次 I/O 可以取得 1 or 多個 Page 的資料,會因不同因素(e.g. Disk partition)有所不同
- 單次 I/O 無法只讀取單一筆 (Row) 的資料,而是讀取 Page 裡多筆資料,資料庫再把其他不需要的資料給過濾掉 → 故每次 query 有不小的成本
Heap
是一種資料結構,用於存放一個個的 Page 資料,多個 Page 組成一個 Heap File
- 要迭代 Heap 找到我們想要的資料是昂貴的開銷
- 建立
索引(Index)可以準確地告訴資料庫要讀取 Heap 裡的哪個部分,也就是只讀取哪些 Page 的資料 → 即 index 可以加速查詢效率的原因
Heap, Page, Tuple 之間的關係圖
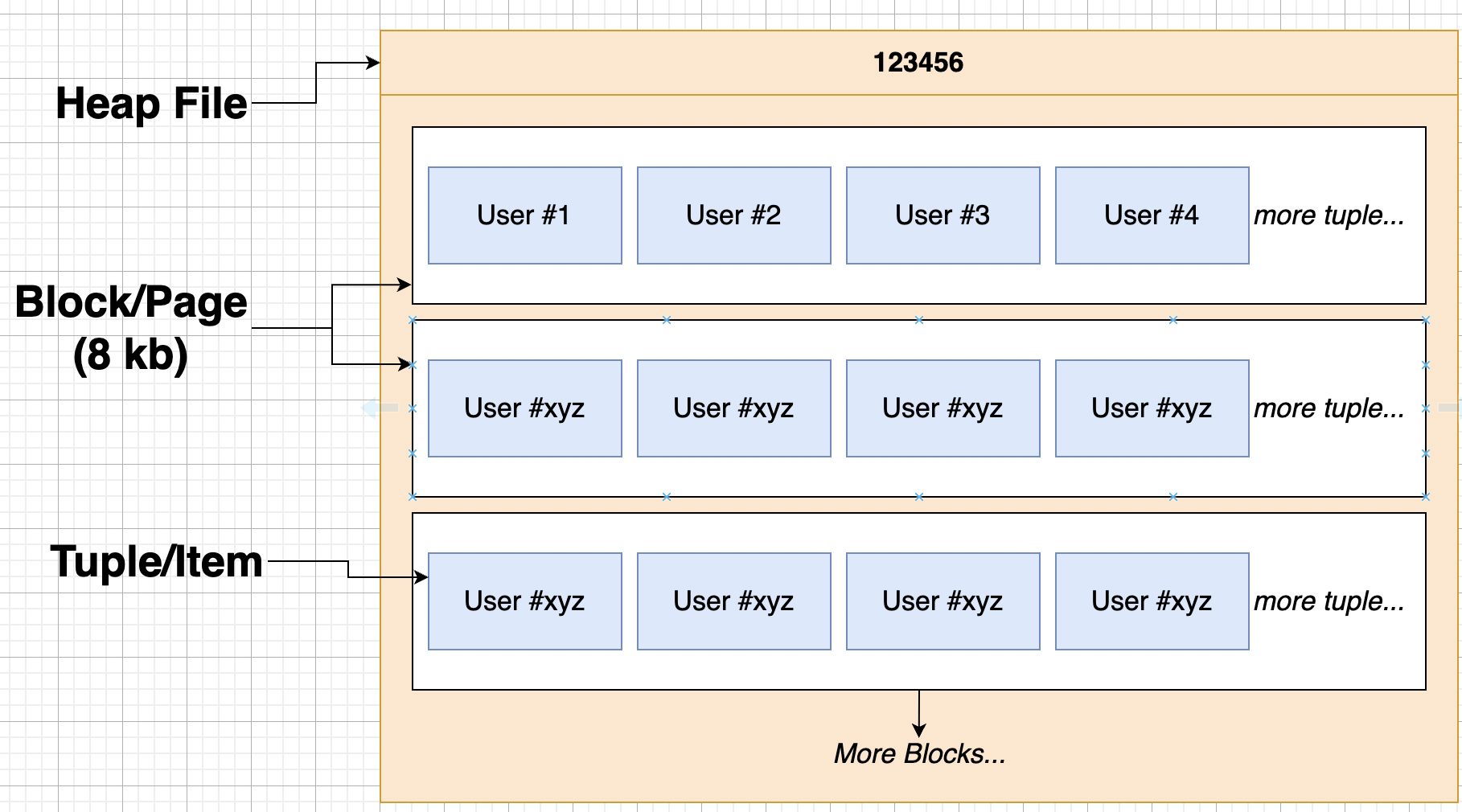
PostgreSQL 將 table 資料都存成一個一個的檔案,我們稱為 Heap 或 Heap files,Heap file 由多個 Block 組成,每個 Block 為 8KB,Block(Page) 裡面的 Item (Tuple),就是存放的資料。
資料庫讀取資料的過程:
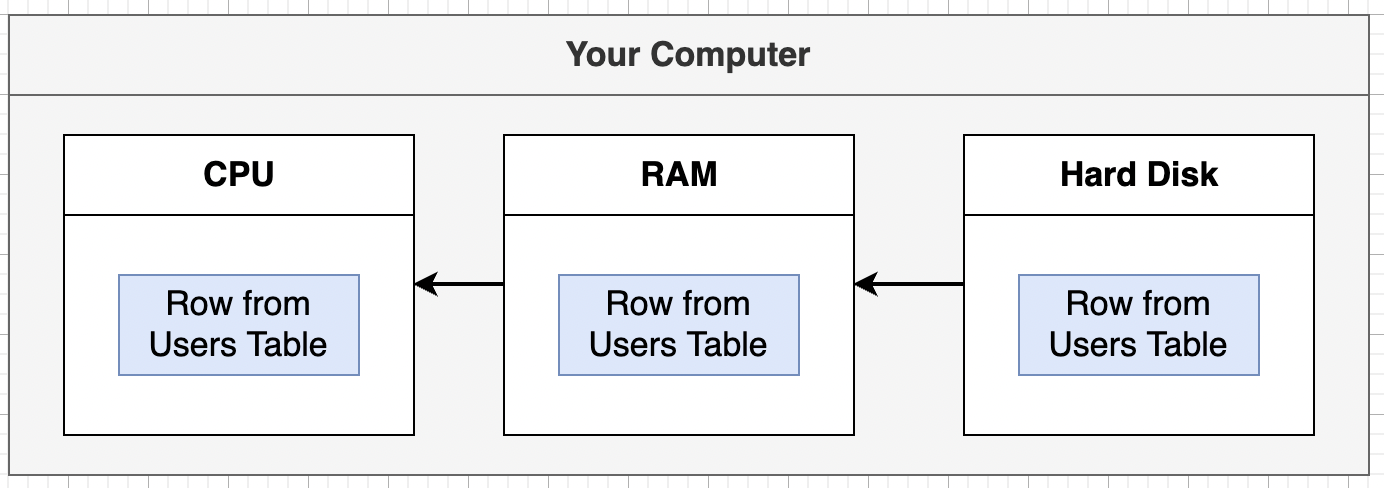
資料庫會從電腦磁碟(Disk)讀取資料表,將資料表裡的資料載入記憶體(Memory),最後移動至 CPU 進行處理。
來看個實際例子: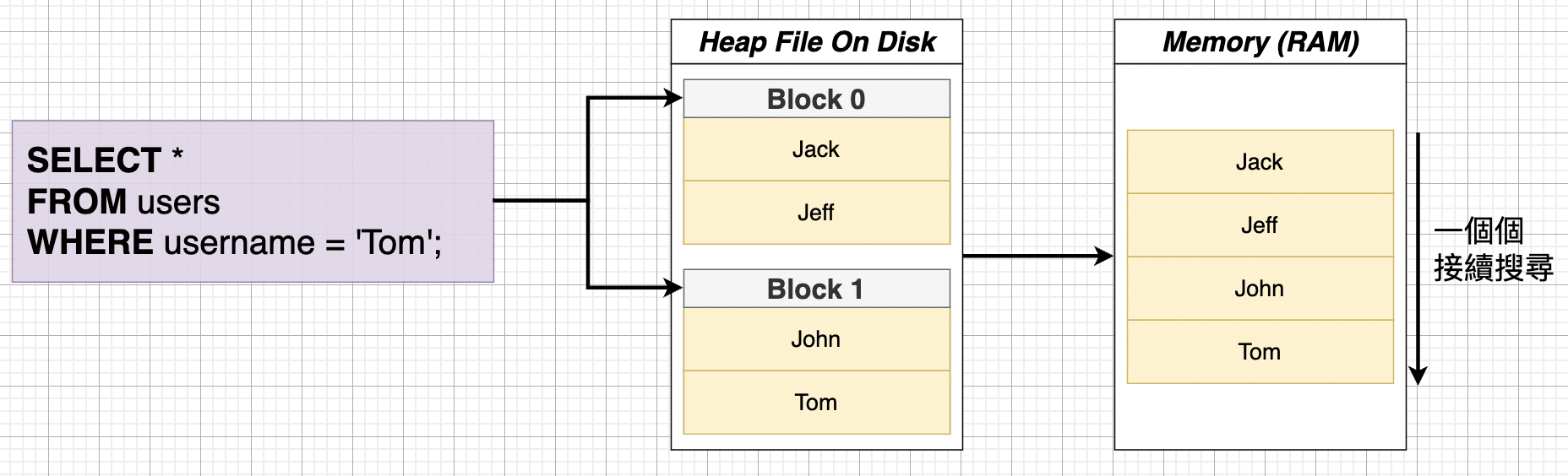
資料庫會先到 Disk 的 Heap File 裡讀取 user 表,載入至記憶體,接著逐筆進行搜尋。
Index
Index (中文作”索引”)是 B+ tree 的資料結構,以犧牲儲存空間、減慢寫入 & 更新資料的速度為代價,換取更好的查詢效率,具有 pointer(指針) 指向 Heap 裡的資料,這些 pointer 在意義上是個數值,指向資料庫的 TID(row id),TID(row id) 會包含許多有關於 Heap 裡 Page 的 meta data。
關於 Index 的幾個重點:
- 可以對 1 or 多個欄位下 Index
- Index 會準確地告訴資料庫在 Heap 中取的哪個 Page,而不是把 Heap 裡的每個 Page 都掃過一遍
- Index 會被存在獨立 Heap File 的 Page 裡,一樣透過 I/O 從 Disk 裡讀取 Index 資料
- 從 Disk 取出的 Index 資料,會放入 Memory,如果 Index 過大的話,可能遇到非所有 Index 都能放進 Memory 搜尋 → 故單個 Index 的大小盡可能縮小,才能夠放入 Memory 快速地搜尋
Index 是如何存放在 Disk? (簡化的版本)
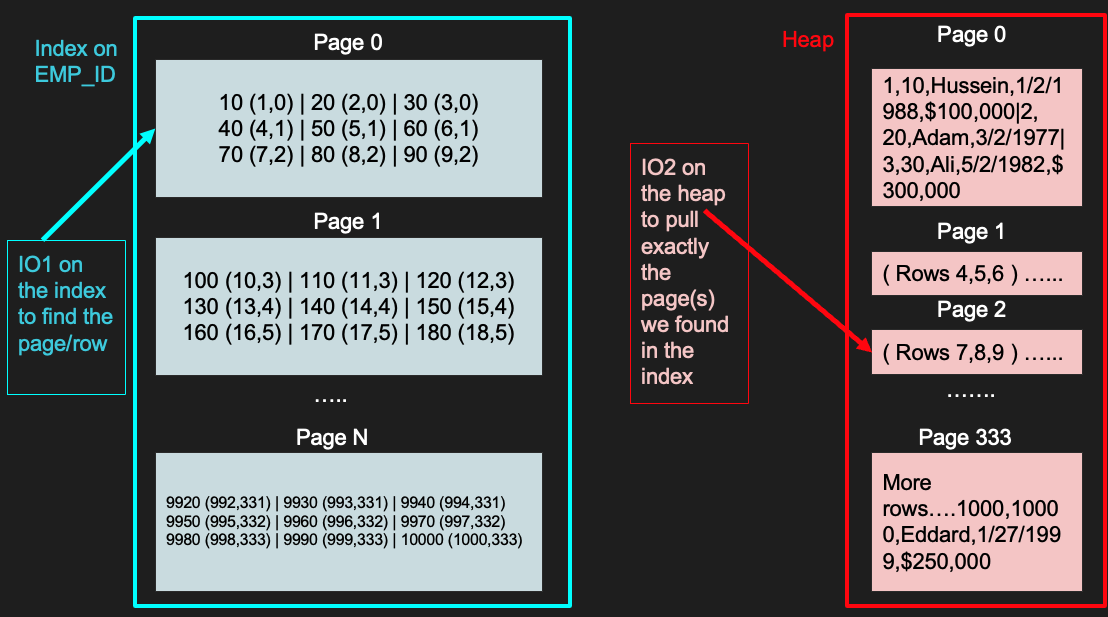
Index 表裡面存放了被設置為 Index 的欄位內容作為 key 值,以及該 key 對應 Page(Block), Row(Tuple) 的位置,也就是「儲存的 key 值與 TID 的配對關係」。
以上圖表為例,EMP_ID 欄位被設置為 Index,Key 為 EMP_ID 的值,其中 10 (1,0) 可以解讀為:Key = 10, TID = (offset = 1, block = 0)。
這組數字表示 EMP_ID 為 10 的值位在第 0 個 Page(Block) 裡的第 1 個 Tuple。
注:offset 表偏移量
直接從 index 裡取得 TID,藉由取得的 TID 值,快速定位該值是位在哪個 Page(Block) 內的第幾個 Row(Tuple)
另外,在使用 Index 的過程中,資料庫會經歷兩次 I/O, 第一次 I/O (IO1)去專門存放 Index 的目標資料的 Heap File,從 Index 裡面取出目標 Page 和 Row 所在位置後,以此為依據進行第二次 I/O (IO2),到存放原始資料的 Heap File 裡找出目標資料。
小結
前面內容討論資料庫儲存資料的幾個重要結構: Heap, Page, Tuple, Index,以及他們之間的關系,最後討論 SQL 執行查詢語句時,是如何跟 Disk 要資料載入記憶體,另外,知道結構之間的關係將有助於未來優化 SQL 語句。